Deep Neural Networks (DNNs) form the backbone of modern machine learning. One of the strength of DNNs is its high expressivity power. This capability to capture any flexible data representation allows deep neural networks to have widespread use from biology or weather prediction.
Universal Approximation Theorem
Universal Approximation Theorem(UMT) states that any feedforward networks with a linear output layer, one hidden layer, activation function t can appoximate any continuous functions on a subset of
Although a Feedforward Neural Network with a single layer can represent any function, the width has to be infinite. The UMT doesn’t guarantee whether the model can be learned or generalized properly.
Proof
A neural network can model any function given a sample size and dimensions if: For every sample set and and every function defined on this sample set , we can find a set of weights such that
Let us prove the simple case:
There exists a two-layer neural network with ReLU activations and weights that can represent any function on a sample of size in dimensions.
First we would like to construct a two-layer neural network . The input is a -dimensional vector, . The hidden layer has hidden units, associated with a weight matrix , a bias vector and ReLU activation function. The second layer outputs a scalar value with weight vector and zero biases.
The output of network for an input vector can be represented as follows:
where is the -th column in the matrix.
Given a sample set and target values , we would like to find proper weights , so that , ∀.
Let’s combine all sample points into one batch as one input matrix . If set , would be a square matrix of size .
We can simplify to have the same column vectors across all the columns:
Let , we would like to find a suitable and such that This is always achievable because we try to solve unknown variables with constraints and are independent. Set random , sort the values. In between each set a value. Then becomes a lower triangular matrix, due to the above condition.
It is a nonsingular square matrix as , so we can always find suitable to solve (In other words, the column space of is all of and we can find a linear combination of column vectors to obtain any ).
You can also see the experimental results at UMT Proof
Why NN can even model noise?
Since, we now know any NN are universal approximaters. We can safely assume that they are also able to learn unstructed noice perfectly.
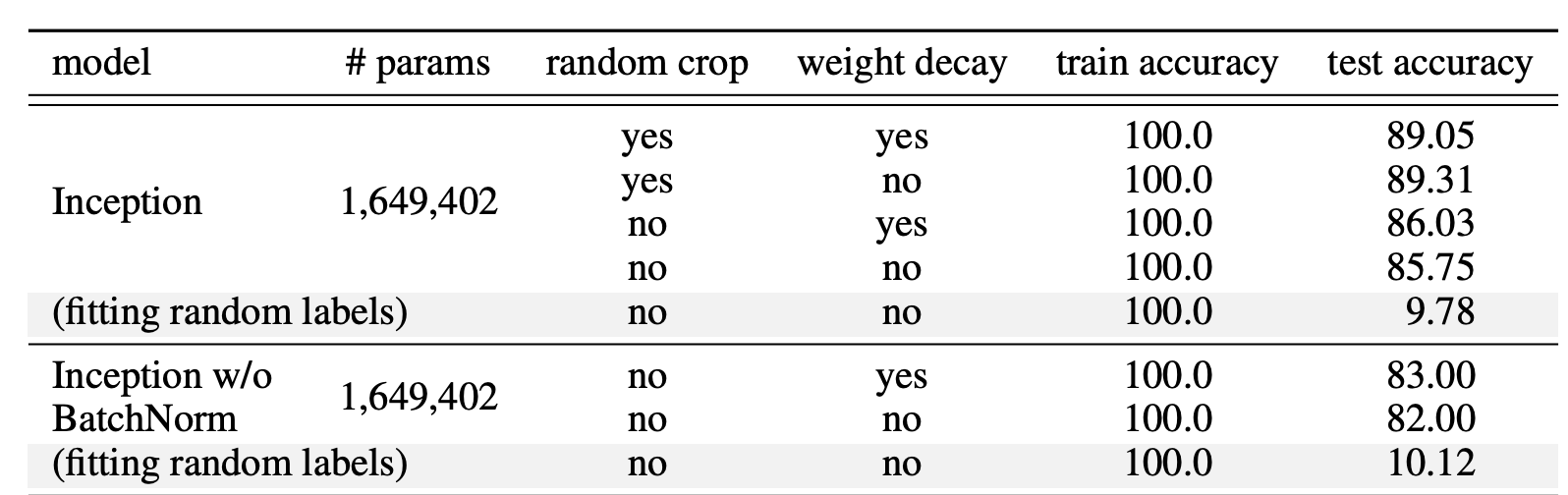
If labels of image classification dataset are randomly shuffled, the university principle of NN can still acheive net zero training loss. This doesn’t change with any degree of regularization.
Regularization is a not always the right answer
Regularization is a common technique to prevent overfitting. However, it is works very differently in the context of neural networks. In contrast to traditional methods, regularization in neural networks acts as a tuning paramter that helps improve the test error. No single regularization seems to be critical independent of other terms. Thus, it is unlikely that regularizers are the fundamental reason for generalization.
Just move bro
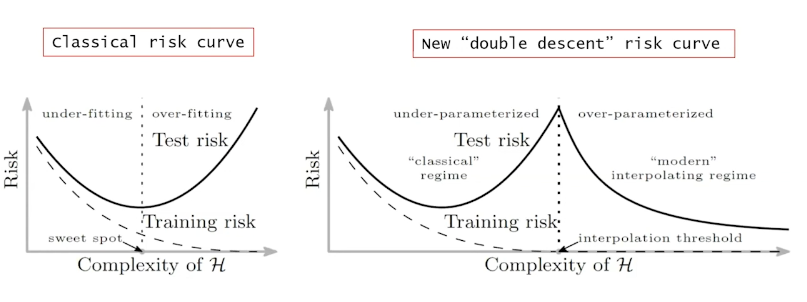
Considering a neural network with a great number of parameters, forming a high-dimensional parameter space, when learning happens on this high-dimensional objective landscape. The shape of the parameter space manifold is critical. For example, from the Batch Normalizations page, we can clearly see that a smoother manifold is benficial for optimization. It allows us to have more predictive gradients and larger learning rates.
Even though the parameter space is huge, fortunately we don’t have to worry too much about the optimization process getting stuck in local optima, as it has been shown that local optimal points in the objective landscape almost always lay in saddle-points rather than valleys. In other words, there is always a some dimensions containing paths to leave local optima and keep on exploring. As they say Just move bro.
There is some mindblowing math here specifically related to saddle points. Just to summarize:
- Critical points concentrate along a monotonically increasing curve in the plane.
- Eigenvalues do not seem to be exactly distributed according to the semicircular law, their distribution does shift to the left as the error increases
- A plateau around any critical point of the error function of a neural network.
- A trust region approach is a practical way to escape saddle points. This is done by making all the eigenvalues of the Hessian positive by adding a term to the diagonal of the Hessian matrix. Rescale the gradient by the inverse of the modified eigenvalyes ( decrease the step size in general). To ensure descent along every eigen-directions, one must increase until all the eigenvalues are positive.
Deep networks perform
Classic difference between NN and traditional ML
Heterogeneous Layer Robustness
Lottery ticket
Neural tangent kernel
Infinite width networks
Deterministic NTK
Linearized NTK
Lazy training
References:
Source: 1 1/2 lessons of deep learning